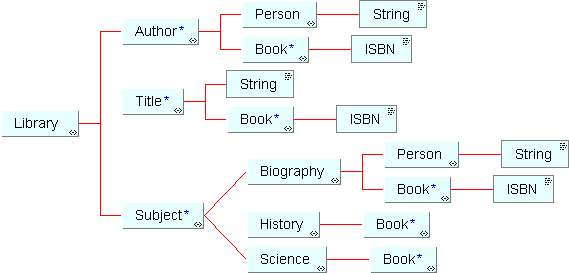
The corresponding DTD is:
<!ELEMENT Library (Author* , Title* , Subject* )>
<!ELEMENT Author (Person , Book* )>
<!ELEMENT Title (String , Book* )>
<!ELEMENT Subject (Biography | History | Science )>
<!ELEMENT Person (String )>
<!ELEMENT Book (ISBN )>
<!ELEMENT String (#PCDATA )>
<!ELEMENT Biography (Person , Book* )>
<!ELEMENT History (Book* )>
<!ELEMENT ISBN (#PCDATA )>
<!ELEMENT Science (Book* )>
We want to express the query: Find all books that are either about or written by some person. To answer this query, we need the following navigation:
Strategy:
{ Library -> Author
Author -> Book
Library -> Biography
Biography -> Book }
source: Library target: Book
To express this in XML's XPath notation, we would write (check the details):
merge(Library//Author//Book, Library//Biography//Book)
The visitor would have around methods attached to Author and Biography and only proceed if the Person (e.g., host.get_person() or host.get_subject()) was who we're looking for. Note that we can't just use the path Library -> Person -> Book since there's no path from Person to Book.
Now consider the following modified XML schema L2.
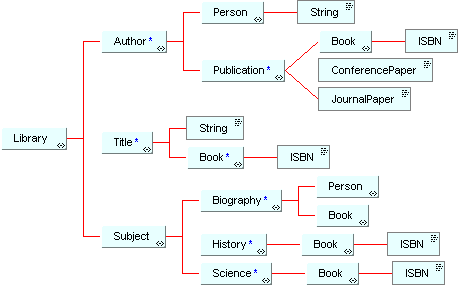
The corresponding DTD is:
<!ELEMENT Library (Author* , Title* , Subject )>
<!ELEMENT Author (Person , Publication* )>
<!ELEMENT Title (String , Book* )>
<!ELEMENT Subject (Biography* , History* , Science* )>
<!ELEMENT Person (String )>
<!ELEMENT Book (ISBN )>
<!ELEMENT String (#PCDATA )>
<!ELEMENT Biography (Person , Book )>
<!ELEMENT History (Book )>
<!ELEMENT ISBN (#PCDATA )>
<!ELEMENT Science (Book )>
<!ELEMENT Publication (Book | ConferencePaper | JournalPaper
)>
<!ELEMENT ConferencePaper (#PCDATA )>
<!ELEMENT JournalPaper (#PCDATA )>
In L2, an author may have different kinds of publications, not just books. Also the subject area has been reorganized. Instead of having a heterogeneous list of subjects, the subjects are now in a fixed order: first biographies, then history books and then science books. Despite these changes to the schema L1, we can still use exactly the same query.
Notes:
We use a flattened form of XML schemas to avoid a discussion of navigation
through common parts. We assume that the books are stored in a separate
list and they are referenced by their unique ISBN number.
In XML we cannot talk about part names directly. A modified DTD notation would be preferrable (changes underlined):
<!ELEMENT Library ( <byAuthor> Author* , <byTitle>
Title* , <bySubject> Subject* )>
<!ELEMENT Author (Person , <booksWritten> Book*
)>
<!ELEMENT Title (String , <booksNamed> Book*
)>
<!ELEMENT Subject (Biography | History | Science )>
<!ELEMENT Person ( <name> String )>
<!ELEMENT Book (ISBN )>
<!ELEMENT String (#PCDATA )>
<!ELEMENT Biography ( <subject> Person , <booksAbout>
Book* )>
<!ELEMENT History ( <booksAbout> Book* )>
<!ELEMENT ISBN (#PCDATA )>
<!ELEMENT Science (<booksAbout> Book* )>
Hopefully, this capability will be included in a new schema standard.
Below we show the UML class diagram for L1.
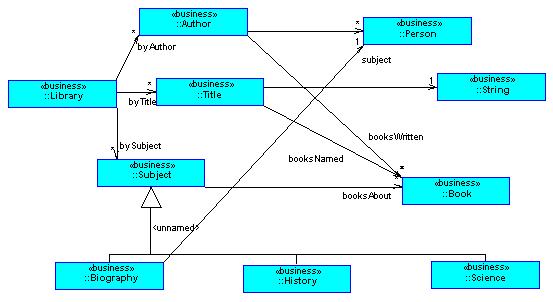
Acknowledgements: The XML schemas were produced with Authority and the UML class diagram with Select Enterprise.