Harriet J. Fell

Prof. Fell's recent research focuses on automatic analysis of the acoustic signals of
speech and pre-speech (babbles). This is a long-term development project with many
applications. The underlying research is in real-time extraction of features in speech
and speech-like vocalization. The applications involve building GUIs for clinician,
researcher, speaker (adult, child, or infant), and possibly a parent.
Current Projects
visiBabble
The visiBabble system processes infant vocalizations in real-time. It responds to the
infant's syllable-like productions with brightly colored animations and records the
acoustic-phonetic analysis. The system reinforces the production of syllabic utterances
that are associated with later language and cognitive development.
Vocalization Age

The Early Vocalization Analyzer (EVA) is a computer program that automatically analyzes
digitized acoustic recordings of infant vocalizations. Using the landmark detection theory
of Stevens et al for the recognition of phonetic features in speech, EVA detects syllables
in vocalizations produced by infants. Landmarks are grouped into standard syllable
patterns and syllables are grouped into utterances. Statistics derived from these groups
and the underlying features are used to derive a "vocalization age" that can clinically
distinguish infants who may be at risk for later communication or other developmental
problems from typically developing infants in the six to fifteen month age range.
Reading Out Loud

Reading Aloud is software to help beginning readers use appropriate prosody while reading
out loud. It will provide readers with visual prosodic cues for reading out loud. The
software will guide readers through a series of modules that introduce one prosodic
feature (duration, loudness, or pitch) at a time. Each prosodic feature will correspond
to a given visual cue. An adult model will be used to develop the target prosody.
Babble Corpora
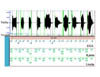
We have and continue to collect and digitize samples of infant vocalizations. We are
starting to build a corpora (database) of these vocalizations. We have transcriptions of
the recordings and information on which samples contain particular kinds of sounds, e.g.
fricatives or high vowels. We plan to enlarge this corpora and make it searchable so that
we can automatically try new feature detection code on samples with a particular feature.
© 2006